知识库
知识准备
了解构建 RAG 应用流程
下图展示通过 CNB 的知识库插件 2 步构建 RAG 应用。
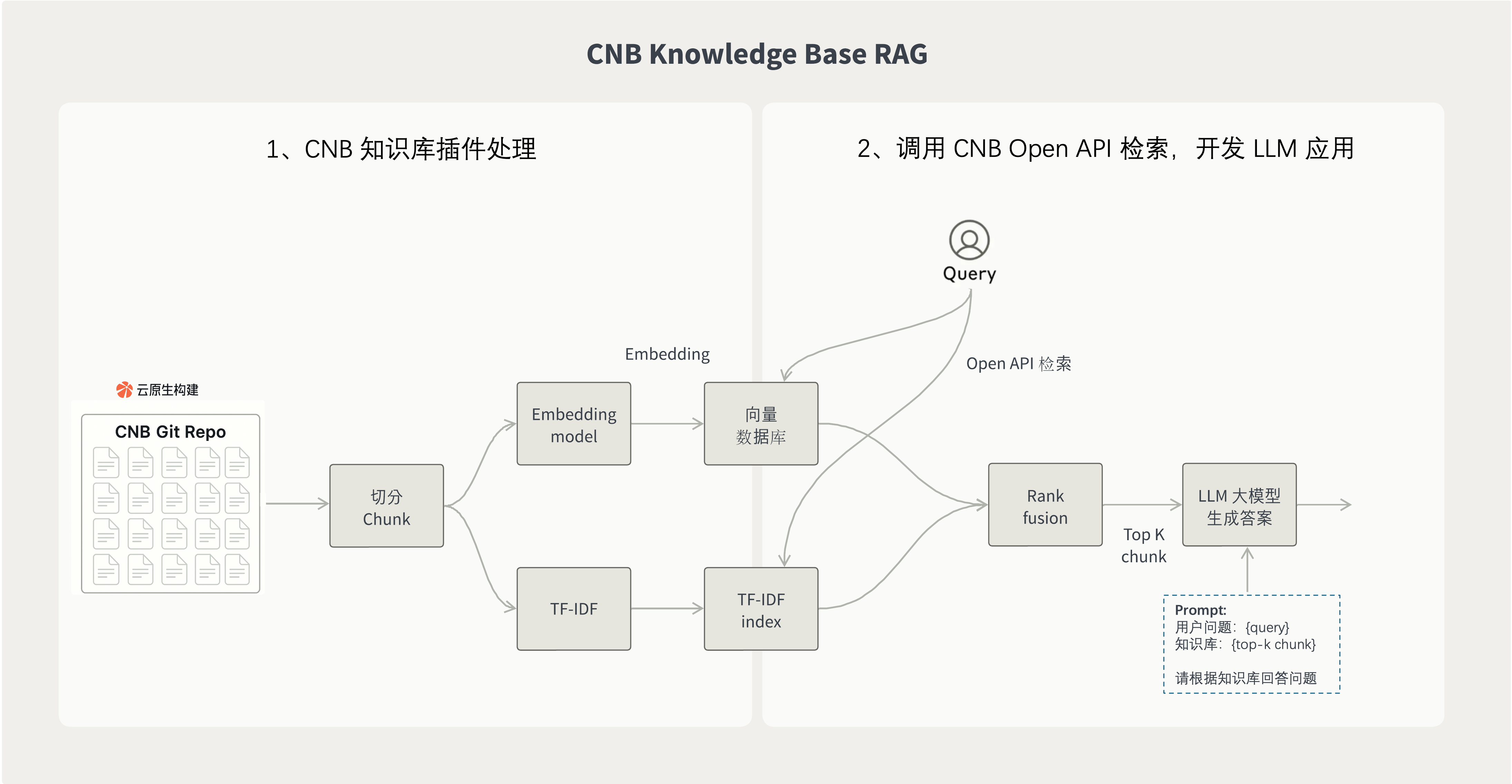
1. 使用知识库插件将仓库的文档导入到知识库
使用 CNB 知识库插件将仓库的文档导入到 CNB 的知识库中, 插件在云原生构建中运行, 会自动处理文档切片、分词、向量化等操作。 知识库构建完成后,可以被下游的 LLM 应用使用。
2. 调用 CNB Open API 检索,开发 LLM 应用
知识库构建完成后,使用 CNB 的 Open API 进行召回,并结合 LLM 模型生成回答。
常见的 RAG 应用运行流程如下:
1.用户提问
2.理解用户问题后,使用 Query 调用知识库检索。如上文所述,使用 CNB 的 Open API 进行检索,获取相关文档片段
3.拿到从 CNB 知识库检索的结果后,构建拼接 Prompt 问题 + 知识上下文,例如拼接后 prompt 一般会这样:
1用户提问:{用户问题}
2
3知识库:
4{从知识库检索到的内容}
5
6请根据以上知识库,回答用户的问题。
4.将拼接后的 prompt 发送给 LLM 模型,生成回答,返回给用户
具体使用方法
步骤 1:配置流水线使用知识库插件
插件镜像名字:cnbcool/knowledge-base
在代码仓库的 .cnb.yml 中配置流水线,使用知识库插件。 如下图配置,当仓库的 main 分支有代码提交时,会触发流水线,自动使用知识库插件对 Markdown 文件进行切片、分词、向量化等处理,并将处理后的内容上传到 CNB 的知识库中。
1main:
2 push:
3 - stages:
4 - name: build knowledge base
5 image: cnbcool/knowledge-base
6 settings:
7 embedding_model: hunyuan
8 include: "**/**.md"
9 exclude: ""
部分插件参数说明如下,如果需要了解更多参数,请参考 cnbcool/knowledge-base 插件文档。
| 参数名 | 说明 | 默认值 | 备注 |
|---|---|---|---|
embedding_model | 嵌入模型 | - | 目前只支持 hunyuan |
include | 指定需要包含的文件 | *(所有文件) | 使用 glob 模式匹配,默认包含所有文件 |
exclude | 指定需要排除的文件 | 空 | 使用 glob 模式匹配,默认不排除任何文件 |
chunk_size | 指定文本分块大小 | 1500 | |
chunk_overlap | 指定相邻两个分块之间的重叠token数量 | 0 |
步骤 2:使用知识库
知识库构建完成后,可以通过 Open API 对该仓库所属知识库进行查询检索,召回后的内容可以结合 LLM 模型生成回答。
:::tip
开始之前,请阅读:CNB Open API 使用教程
访问令牌需要权限:repo-code:r(读仓库代码)
注意: {slug} 应替换为仓库 slug,例如 CNB 官方文档知识库的仓库地址为
https://cnb.cool/cnb/docs, 则 {slug} 就是 cnb/docs
:::
接口信息
- URL:
https://api.cnb.cool/{slug}/-/knowledge/base/query - 方法: POST
- 内容类型: application/json
请求参数
请求体应为 JSON 格式,包含以下字段:
| 参数名 | 类型 | 必填 | 描述 |
|---|---|---|---|
| query | string | 是 | 要查询的关键词或问题 |
请求示例
1{
2 "query": "云原生开发配置自定义按钮"
3}
响应内容
响应为 JSON 格式,包含一个结果数组,每个结果包含以下字段:
| 字段名 | 类型 | 描述 |
|---|---|---|
| score | number | 匹配相关性分数,范围 0-1,值越高表示匹配度越高 |
| chunk | string | 匹配的知识库内容文本 |
| metadata | object | 内容元数据 |
metadata 字段详情
| 字段名 | 类型 | 描述 |
|---|---|---|
| hash | string | 内容的唯一哈希值 |
| name | string | 文档名称 |
| path | string | 文档路径 |
| position | number | 内容在原文档中的位置 |
| score | number | 匹配相关性分数,值越高表示匹配度越高 |
响应示例
1[
2 {
3 "score": 0.8671732,
4 "chunk": "该云原生远程开发解决方案基于Docker...",
5 "metadata": {
6 "hash": "15f7a1fc4420cbe9d81a946c9fc88814",
7 "name": "quick-start",
8 "path": "vscode/quick-start.md",
9 "position": 0,
10 "score": 0.8671732
11 }
12 }
13]
使用示例
cURL 请求示例
注意: {slug} 应替换为仓库 slug,例如 CNB 官方文档知识库的仓库地址为
https://cnb.cool/cnb/docs, 则 {slug} 就是 cnb/docs,替换后完整的请求地址:https://api.cnb.cool/cnb/docs/-/knowledge/base/query
1curl -X "POST" "https://api.cnb.cool/{slug}/-/knowledge/base/query" \
2 -H "accept: application/json" \
3 -H "Content-Type: application/json" \
4 -H "Authorization: Bearer ${token}" \
5 -d '{
6 "query": "云原生开发配置自定义按钮"
7}'
获取到的响应内容可以结合 LLM 模型生成回答。
RAG 小应用示例
例如,一个使用 JavaScript 实现的简单 RAG 应用示例代码如下:
1import OpenAI from "openai";
2
3// 配置
4const CNB_TOKEN = "your-cnb-token"; // 替换为你的 CNB 访问令牌, 需要权限:`repo-code:r`(读仓库代码)
5const OPENAI_API_KEY = "your-openai-api-key"; // 替换为你的 OpenAI API 密钥
6const OPENAI_BASE_URL = "https://api.openai.com/v1"; // 或者你的代理地址
7const REPO_SLUG = "cnb/docs"; // 替换为你的仓库 slug
8
9// 初始化 OpenAI 客户端
10const openai = new OpenAI({
11 apiKey: OPENAI_API_KEY,
12 baseURL: OPENAI_BASE_URL,
13});
14
15async function simpleRAG(question) {
16 // 1. 调用CNB知识库检索
17 const response = await fetch(
18 `https://api.cnb.cool/${REPO_SLUG}/-/knowledge/base/query`,
19 {
20 method: "POST",
21 headers: {
22 "Content-Type": "application/json",
23 Authorization: `Bearer ${CNB_TOKEN}`,
24 },
25 body: JSON.stringify({ query: question }),
26 },
27 );
28
29 const knowledgeResults = await response.json();
30
31 // 2. 提取知识内容(这里假设取全部结果)
32 const knowledge = knowledgeResults.map((item) => item.chunk).join("\n\n");
33
34 // 3. 调用OpenAI生成回答
35 const completion = await openai.chat.completions.create({
36 model: "gpt-4.1-2025-04-14",
37 messages: [
38 {
39 role: "user",
40 content: `问题:${question}\n\n知识库:${knowledge}\n\n请根据知识库回答问题。`,
41 },
42 ],
43 });
44
45 return completion.choices[0].message.content;
46}
47
48// 使用示例
49const answer = await simpleRAG("如何开发一个插件?");
50// 输出结合知识库的回答
51console.log(answer);